需要予測AIの仕組みをAIエンジニアがモデルを作って解説!気象により影響を受ける商品とは?



需要予測AIというキーワードが製造業を中心に盛んになっていますね。
というのも、この人材不足&サスティナビリティが叫ばれる昨今、在庫の無駄な処理や人的リソース削減は喫緊の課題となっているためです。
しかし、その仕組みはそもそも何なのか?と疑問に思う企業担当者さん、エンジニアの皆さんもおられるかと思います。
そこで本記事では需要予測AIの仕組みについて概論を展開し、終盤では筆者が実際のデータを用いて開発をして詳細に解説します。
需要予測AIとは

需要予測AIとは、売れるタイミング・売れる量を先読みして、企業の意思決定を支える技術です。
POSデータやトレンド、天気、イベント情報など、多様なデータを横断的に解析し、精度の高い予測を出せるのが特徴と言えるでしょう。
メリットとしては、在庫の持ちすぎ・欠品といったリスクを減らし、生産や仕入れの無駄を削減したり、プロモーション時期の最適化や人員配置の調整など、リソースの効率化にもつながります。
特に昨今は、小売・飲食・物流・製造といったリアルビジネスで導入が進んでおり、「過去の経験値」や「勘」では捉えきれない需要の波を、AIで定量的に扱えることが強みです。
将来の数値を予測するAIのこと
需要予測AIはざっくり言えば「過去データを学習して、未来を数値で出すモデル」です。
統計的なアプローチで、時系列分析、回帰、ニューラルネットなど様々な手法を使ってトレンド・季節性・外部要因などをくみ取ります。
例えば、「雨が降ると売れる傘」や「祝日前に伸びる惣菜」「月末に落ちるアクセス数」など、法則性を数字ベースで拾い、将来の売上や在庫推移を予測してくれます。
さらに重要なのは、「学習して終わり」じゃない点と言えます。
リアルタイムでデータを取り込み、状況に応じてモデルを再学習させることで、急な変化(パンデミックや天候急変)にも追従できる柔軟性も考慮した設計が求められます。
食品業界での事例
食品業界では需要予測AIの活用が進んでいます。
民間単位ではマーケティング活動を支援するシステムサービスなどが台頭してきて、官庁単位では食品ロス削減を目的にとした食品メーカー・小売・卸が情報を共有し、製造過多を防ぐ仕組みを構築中であったりと、官民の両方で需要予測AIに対する取り組みが盛んです。
しかし、こういった取り組みがあっても、地方中小企業などの導入が遅れている企業では、地域・時期ごとの需要を把握できず、廃棄が発生しやすいのが現状です。
気象情報での事例
需要予測AIは、気象情報の応用も進んでいます。
お天気キャスターで有名な株式会社ウェザーニューズは、独自開発したAIシステムを使い、電力需要の予測サービスを提供を始めました。
このシステムでは、電力会社の最新の消費電力データと、ウェザーニューズが保有する気象データを組み合わせ、AIが30分ごとに再学習を行いながら予測精度を高めていきます。
「ウェザーニュース電力需給予報」という名前で誰でも使用が可能なので、お手隙の際にサイトを覗いてみてください。
需要予測AIモデルを作る流れ
需要予測AIモデルの構築には、体系的なプロセスが必要です。
これはAI開発のみならずシステム開発まわり全般に言えることですが、結局は「何をしたいのか」から逆算したアクションを取ることが求められます。
ここでは需要予測AIの開発において重要な流れを3つに分けて解説していきます。
データセットの作成
需要予測AIの精度を左右するのは「データセットの質」と言われています。ここを雑に行なってしまうと、どんな高性能なモデルでも意味を成しません。(Garbage in, Garbege out.)
データの収集対象は、売上履歴・コスト・季節性・天候など、「需要バランスに影響しそうな情報」になってきます。
事業ドメイン次第ではSNSトレンド、競合の動きも使える変数になりえます。
データを集めたらそこで終了ではなく、次は前処理が必要です。
データに穴があってはいけないので、欠損値の補完。偏りがあってはいけないので、異常値の除去。このような作業を「データクレンジング」と呼び、AI学習に使える状態へ整える工程を指します。
最後に、特徴量エンジニアリングといったAIが学習する対象を明確に定義して、データセットが完成します。
ちなみに、AI開発で最も工数がかかる可能性が高いのがこのデータセットの作成だとも言われています。
アルゴリズムの選定
データが揃ったら、次は需要予測で使うアルゴリズムの選定をします。
選定の基準は「精度」と「処理コスト」のバランスがすべてです。どれだけ高精度でも処理が重すぎると現場運用には向きません。逆に、軽くても精度が出なければ意味がないでしょう。このバランス感覚は時たま定性的な判断が求められるため、ビジネス解像度の高いエンジニアが担当すべき工程といえます。
具体的には、ランダムフォレストやLightGBMなどのツリー系モデルは、非線形な関係やカテゴリ変数にも強く、処理も高速です。
最近はLTransformerといった深層学習系も選択肢に入りますが、精度は出やすい反面、解釈性や学習コストがネックになることもあります。
この工程での精査が甘いと、「動くけど意味がないAI」が出来上がってしまうため、注意が必要です。
モデルの学習
アルゴリズムが決まったら、いよいよモデルの学習フェーズに入ります。
学習には、基本的に損失関数を最小化する最適化アルゴリズムを使います。モデルがデータ内のパターンをうまく捉えられるよう、徐々に重みを調整していく流れのことです。
学習中は、精度・損失・スコアなどを常にモニタリングし、必要があればフィードバックしてモデル構造や特徴量を再調整していきます。
この繰り返しの中で現場で使える需要予測モデルが仕上がっていくため、場合によっては学習フェーズだけで相当な工数がかかってしまうこともありえます。
筆者が需要予測AIモデルを開発して仕組みを解説
では、ここからは筆者が実際に需要予測AIモデルを開発して、その「仕組み」と「どんなことができるのか」を視覚化していきたいかと思います。
本節では概論と実装に至るデータ整形、モデルの学習までをスクリーンショットと共にお見せしてまいりますので、参考にしてください。
気象で売上が影響を受ける商品を推測する
AIモデルを開発する際に最も大事なことは、「何をしたいのか」を明確にイメージし、「何を推測するAIを作るのか」を決め、「どんなデータを使用するか」という上流〜下流までを最初に定義することです。
何をしたいのかわからずAIを作ろうとしても何も成果が上がるものは生まれません。
そして、本記事では「気象で売上が影響を受ける商品を探す」ということを目的にAIモデルを開発してみたいと思います。
実際に製造業の現場で役に立つほどのものは作れませんが、個人のPCでできる範囲で実現してみましょう。
使用するデータ
「気象で売上が影響を受ける商品を探す」のであれば、必要となるデータは以下のとおりです。
- 期間ごとの気象データ
- 期間ごとの商品売上データ
気象データは比較的手に入りやすいイメージがありますが、商品売り上げは企業情報の制約や正確性に欠けるデータもあるかと思いますので、今回は以下のデータを使用します。
気象庁のデータは文字通り過去の気象データをさかのぼって取得することができるもので、経済産業省のデータは「全国のPOSシステムから抽出した小売店の商品販売動向」を取得することができるデータです。
大分類に「スーパーマーケット」「コンビニエンスストア」「ホームセンター」「ドラッグストア」があり、商品分類には「食品」「飲料」「日用品」「化粧品」「ヘルスケア(医薬品など)」が含まれた合計20種類のカテゴリー分けがされています。
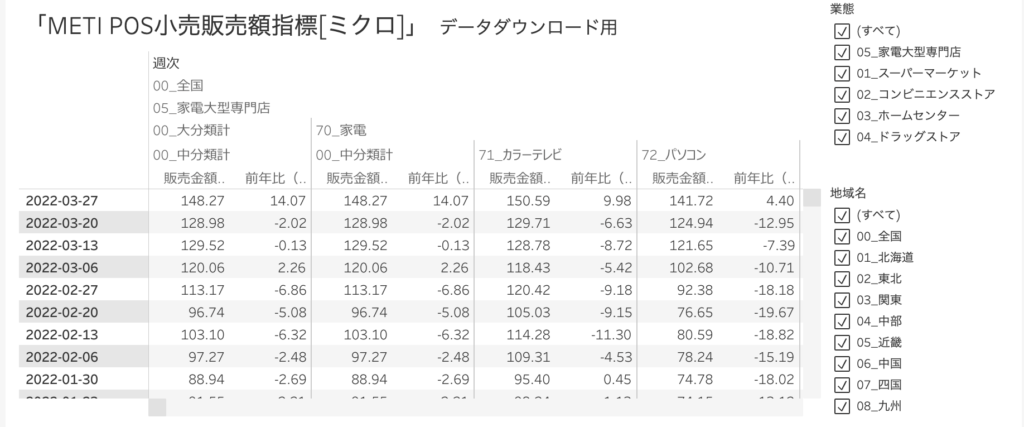
このデータは販売額指数100という数値を平均の指標とし、それ以上を「よく売れている」、それ以下を「あまり売れていない」と判断することができるようになっています。
そして、この2つのデータを掛け合わせて17,655件のデータ数をもつ「10年間の気象と小売店販売額に関するデータセット」を整形することができました。
なお今回整形したデータセットは以下のリンクに貼り付けておりますので、ご興味のある方はご覧ください。
AI開発言語・アルゴリズム

今回開発するために使用する言語はPythonです。データ処理をするにも、学習させるにもやはり便利すぎる。
そして、扱うアルゴリズムは「LightGBM(Light Gradient Boosting Machine )」というもので、目的となる変数を表現する「教師あり学習」と呼ばれる分野のデータ分析方法の一つです。
今回は単一ラベル(〇〇は男、△△は女のような0か1かの判定)ではなく、前述したような複数の種類に別れる「どの商品に属するか」を他変数で予測したいため、このアルゴリズムを採用しました。

このアルゴリズムは「決定木」と呼ばれるあるなしクイズのような構造をさらに複雑化させたようなもので、目的変数に対する学習データの分割を大量に行うことで正解との誤差を縮めて行くことができます。
学習の結果・評価
このモデルを学習させた後、実際の天気を打ち込むと「その日の天候の各商品売上指数はいくつか」が予測されるようになります。
例えば、この記事を書いている時点の天気は「とても暑くて雨も降らないカラッとした日」でした。
- 最高気温: 37度
- 最低気温: 27度
- 降水量: ほぼゼロ
- 日照時間: 12時間
これをインプットしてみたときの結果はこちらです。
| 店舗種別 | カテゴリ | 値 |
|---|---|---|
| スーパーマーケット | 食品 | 101.91 |
| スーパーマーケット | 飲料 | 109.66 |
| スーパーマーケット | 日用品 | 97.03 |
| スーパーマーケット | 化粧品 | 83.29 |
| スーパーマーケット | ヘルスケア | 115.66 |
| スーパーマーケット | その他 | 100.06 |
| コンビニエンスストア | 合計 | 107.61 |
| コンビニエンスストア | 食品 | 89.13 |
| コンビニエンスストア | 飲料 | 102.45 |
| コンビニエンスストア | 日用品 | 134.53 |
| コンビニエンスストア | 化粧品 | 115.43 |
| コンビニエンスストア | ヘルスケア | 161.01 |
| コンビニエンスストア | その他 | 94.92 |
| ホームセンター | 合計 | 94.46 |
| ホームセンター | 食品 | 95.92 |
| ホームセンター | 飲料 | 127.29 |
| ホームセンター | 日用品 | 83.24 |
| ホームセンター | 化粧品 | 99.04 |
| ホームセンター | ヘルスケア | 97.25 |
| ドラッグストア | 合計 | 102.89 |
| ドラッグストア | 食品 | 95.31 |
| ドラッグストア | 飲料 | 111.66 |
| ドラッグストア | 日用品 | 110.61 |
| ドラッグストア | 化粧品 | 108.13 |
| ドラッグストア | ヘルスケア | 101.86 |
では逆に「とても寒くて湿度の低い乾燥した日」だった今年の2月あたりの天気ではどうでしょうか。
- 最高気温: 6.2度
- 最低気温: 3.4度
- 降水量: ほぼゼロ
- 日照時間: 9時間
| 店舗種別 | カテゴリ | 値 |
|---|---|---|
| スーパーマーケット | 食品 | 102.55 |
| スーパーマーケット | 飲料 | 94.25 |
| スーパーマーケット | 日用品 | 92.83 |
| スーパーマーケット | 化粧品 | 81.67 |
| スーパーマーケット | ヘルスケア | 147.23 |
| スーパーマーケット | その他 | 98.62 |
| コンビニエンスストア | 合計 | 89.48 |
| コンビニエンスストア | 食品 | 91.04 |
| コンビニエンスストア | 飲料 | 93.50 |
| コンビニエンスストア | 日用品 | 113.65 |
| コンビニエンスストア | 化粧品 | 109.89 |
| コンビニエンスストア | ヘルスケア | 230.70 |
| コンビニエンスストア | その他 | 92.58 |
| ホームセンター | 合計 | 94.77 |
| ホームセンター | 食品 | 91.57 |
| ホームセンター | 飲料 | 84.60 |
| ホームセンター | 日用品 | 83.85 |
| ホームセンター | 化粧品 | 99.09 |
| ホームセンター | ヘルスケア | 112.71 |
| ドラッグストア | 合計 | 91.53 |
| ドラッグストア | 食品 | 95.58 |
| ドラッグストア | 飲料 | 97.15 |
| ドラッグストア | 日用品 | 84.51 |
| ドラッグストア | 化粧品 | 102.01 |
| ドラッグストア | ヘルスケア | 110.48 |
この対照的な天候を見比べてみると、“飲料”は夏場に100超えを記録する一方冬場では100を切ったり、冬場の伸び代は“ヘルスケア”であることがわかります。
また、コンビニとドラッグストアでは化粧品の売り上げに差があったりと、単純に気候だけではなく販売チャネルの影響もあるのだなとデータから見て取れます。
まとめ
今回は主に製造業で話題の需要予測AIについて、概論から仕組みまでを実演を踏まえて解説しました。
需要予測AIのプロジェクトを成功させるには、その準備段階からこだわることが肝要です。
是非この記事をご覧の皆さまも、今後需要予測AIを構築する機会がありましたら、この考え方を参考にしてみてください。
参考:受託開発とは?依頼するメリットや見るべきポイント解説! | SES業務管理の統合ツール Fairgrit®公式サイト
おまけ: AIモデルのプログラムコード
from __future__ import annotations
from pathlib import Path
import json
import sys
import warnings
import joblib
import jpholiday
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_absolute_percentage_error as mape
from sklearn.model_selection import TimeSeriesSplit
from sklearn.multioutput import MultiOutputRegressor
from sklearn.linear_model import RidgeCV
pd.options.display.max_rows = 1000
warnings.filterwarnings("ignore")
# -----------------------------
# 定数 & 補助関数
# -----------------------------
MODEL_PATH = Path("weather_sales_model.pkl")
WEATHER_COLS = [
"Precipitation(mm)",
"Average_temperature(℃)",
"Maximum_temperature(℃)",
"Minimum_temperature(℃)",
"Sunshine_duration(hours)",
"Global_solar_radiation(MJ/㎡)",
"Average_cloud_cover",
]
def _read_pos(path: str | Path) -> pd.DataFrame:
return pd.read_csv(path, encoding="utf-16be", sep=",", parse_dates=["Date"], engine="python")
def _read_weather(path: str | Path) -> pd.DataFrame:
return (
pd.read_csv(path, encoding="utf-8-sig", parse_dates=["Date"], engine="python")
.drop(columns=[c for c in ["Total_snowfall_depth(cm)", "Maximum_snow_depth(cm)"] if c in pd.read_csv(path, nrows=0, encoding="utf-8-sig").columns])
)
def load_dataset(pos_path: str | Path, wx_path: str | Path) -> pd.DataFrame:
pos = _read_pos(pos_path)
wx = _read_weather(wx_path)
# 期間を合わせる
start = max(pos["Date"].min(), wx["Date"].min())
end = min(pos["Date"].max(), wx["Date"].max())
pos = pos.query("@start <= Date <= @end").sort_values("Date").reset_index(drop=True)
wx = wx.query("@start <= Date <= @end").sort_values("Date").reset_index(drop=True)
print(f"pos shape: {pos.shape}")
print(f"pos head:")
print(pos.head())
print("="*40)
print(f"wx shape: {wx.shape}")
print(f"wx head:")
print(wx.head())
print("="*40)
# 最近接 (±3 日) でマージ
df = pd.merge_asof(
pos, wx,
on="Date",
direction="nearest",
tolerance=pd.Timedelta("3D")
).dropna(subset=WEATHER_COLS)
# 週次リサンプル
df = (
df.set_index("Date")
.resample("W", label="left", closed="left")
.sum(numeric_only=True)
.reset_index()
)
print(f"df shape: {df.shape}")
print(f"df head:")
print(df.head())
print("="*40)
# デバッグ用出力
if df.empty:
print("[WARN] load_dataset: マージ後の行数が 0 です。期間・tolerance を確認してください。", file=sys.stderr)
else:
print("[INFO] load_dataset: rows after merge & resample →", len(df))
df.to_csv(path_or_buf="dataset.csv")
return df
# -----------------------------
# 特徴量生成
# -----------------------------
def add_features(df: pd.DataFrame) -> pd.DataFrame:
out = df.copy()
# 気象派生
out["temp_diff"] = out["Maximum_temperature(℃)"] - out["Minimum_temperature(℃)"]
out["is_rain"] = (out["Precipitation(mm)"] > 0).astype("int8")
# カレンダー(祝日かどうかも判定したい)
out["dow"] = out["Date"].dt.weekday
out["is_holiday"] = out["Date"].apply(lambda d: int(jpholiday.is_holiday(d)))
# ラグ(週次なので 1=1週前)
for k in range(1, 5):
out[f"tavg_lag{k}"] = out["Average_temperature(℃)"].shift(k)
out[f"rain_lag{k}"] = out["Precipitation(mm)"].shift(k)
return out
# -----------------------------
# 天候感応カテゴリ抽出(線形モデル)
# -----------------------------
def weather_screening(df: pd.DataFrame, y_cols: list[str], cv_folds: int = 5, thr: float = 0.8) -> list[str]:
X = df[WEATHER_COLS].values.astype("float32")
sensitive: list[str] = []
tscv = TimeSeriesSplit(n_splits=cv_folds)
for col in y_cols:
y = df[col].values.astype("float32")
y_true, y_pred, y_naive = [], [], []
for tr, te in tscv.split(X):
model = RidgeCV(alphas=(0.1, 1.0, 10.0))
model.fit(X[tr], y[tr])
y_true.extend(y[te])
y_pred.extend(model.predict(X[te]))
# ナイーブ=前年同週(52 週前)
y_naive.extend([y[i - 52] if i >= 52 else y[i - 1] for i in te])
if mape(y_true, y_pred) < thr * mape(y_true, y_naive):
sensitive.append(col)
return sensitive
# -----------------------------
# モデル学習
# -----------------------------
def train_final_model(df: pd.DataFrame, y_cols: list[str]):
feat_cols = (
WEATHER_COLS
+ ["temp_diff", "is_rain", "dow", "is_holiday"]
+ [f"tavg_lag{k}" for k in range(1, 5)]
+ [f"rain_lag{k}" for k in range(1, 5)]
)
data = df.dropna(subset=feat_cols + y_cols)
X, y = data[feat_cols], data[y_cols]
base_reg = lgb.LGBMRegressor(
n_estimators=400,
learning_rate=0.05,
min_data_in_leaf=5,
min_gain_to_split=0.0,
random_state=1,
verbosity=-1,
)
model = MultiOutputRegressor(base_reg)
model.fit(X, y)
return model, feat_cols, y_cols
# -----------------------------
# 保存、読込、推論
# -----------------------------
def save_model(model, feat_cols, y_cols, path: Path = MODEL_PATH):
joblib.dump((model, feat_cols, y_cols), path)
def load_model(path: Path = MODEL_PATH):
return joblib.load(path)
def predict_sales(model, feature_cols: list[str], y_cols: list[str], wx_dict: dict[str, float]) -> dict[str, float]:
X = pd.DataFrame([{c: wx_dict.get(c, 0.0) for c in feature_cols}])
pred = model.predict(X)[0]
print(y_cols)
print(pred)
return {col: float(v) for col, v in zip(y_cols, pred)}
# -----------------------------
# CLI
# -----------------------------
if __name__ == "__main__":
pos_csv, wx_csv = "final_meti_clean.csv", "final_jma.csv"
predict_only = "--predict-only" in sys.argv
if not predict_only:
# 学習フェーズ
df_raw = load_dataset(pos_csv, wx_csv)
df = add_features(df_raw)
y_cols = [c for c in df.columns if c[0].isdigit()]
# sens_cols = weather_screening(df, y_cols)
# sens_cols = weather_screening(df, y_cols, thr=1.0)
# if not sens_cols:
# print("[WARN] 感応カテゴリなし → 全カテゴリを使用")
# sens_cols = y_cols # フォールバック
sens_cols = y_cols
model, feat_cols, y_cols_final = train_final_model(df, sens_cols)
print("Weather-sensitive categories:", sens_cols)
model, feat_cols, y_cols_final = train_final_model(df, sens_cols)
save_model(model, feat_cols, y_cols_final)
print("Model saved →", MODEL_PATH.resolve())
else:
print("Skip training; load existing model →", MODEL_PATH)
# 推論
model, feat_cols, y_cols_final = load_model()
if sys.stdin.isatty():
print("\n標準入力で気象 JSON を渡すと予測します\n例:\n echo '{\"Average_temperature(℃)\":30,\"Precipitation(mm)\":0}' | python weather_sales_prediction.py --predict-only")
else:
wx_input = json.loads(sys.stdin.read())
print(predict_sales(model, feat_cols, y_cols_final, wx_input))
この記事の著者

児玉慶一
執行役員/ AI・ITエンジニア
SNS
![]()
愛称: ケーイチ
1999年2月生まれ。大学へ現役進学後数ヶ月で通信キャリアの営業代理店を経験。営業商材をもとに100名規模の学生団体を構築。個人事業主として2018年〜2020年2月まで活動したのち、2020年4月に広告営業事業を営む株式会社TOYを創業。同時期にITの可能性を感じプログラミングを始め、現在はITエンジニアとして活動中。2021年にLeograph株式会社に参画し、AI研究開発やWebアプリ開発などを手掛ける。 「Don't repeat yourself(重複作業をなくそう)」「Garbage in, Garbage out(無意味なデータは、無意味な結果をもたらす)」をモットーにエンジニア業務をこなす。
【得意領域】
業務効率化AIモデル開発
事業課題、戦略工程からシステム開発
Webマーケティング戦略からSaaS開発