
【Part1】画像認識AIの仕組みとは?実際に開発して解説してみた



画像認識AIは、現代の技術革新において重要な役割を果たしています。防犯カメラへの応用から生成AIへの転用によるエンタメ性の高いものまで。
そんな中「画像認識AIの仕組みはどうなっているのか?」と、その技術について純粋に疑問を持つ方もいらっしゃいます。
本記事では、まず画像認識AIの基礎的な仕組みについて詳しく解説し、次回「Part2」にて実際に開発を行なった内容を詳細に解説していこうかと思います。
本記事を通じて、画像認識AIの全体像とその実用的な開発方法について理解を深めていただければ幸いです。
画像認識AIに使われる技術とは?
現代の画像認識AIには、最新の技術と強力なライブラリが組み合わさって活用されています。
その用途や目的によって適切な技術アセットの選択も変わってくるため、本節では技術アセットごとについて解説していきます。
CNN(畳み込みニューラルネットワーク)
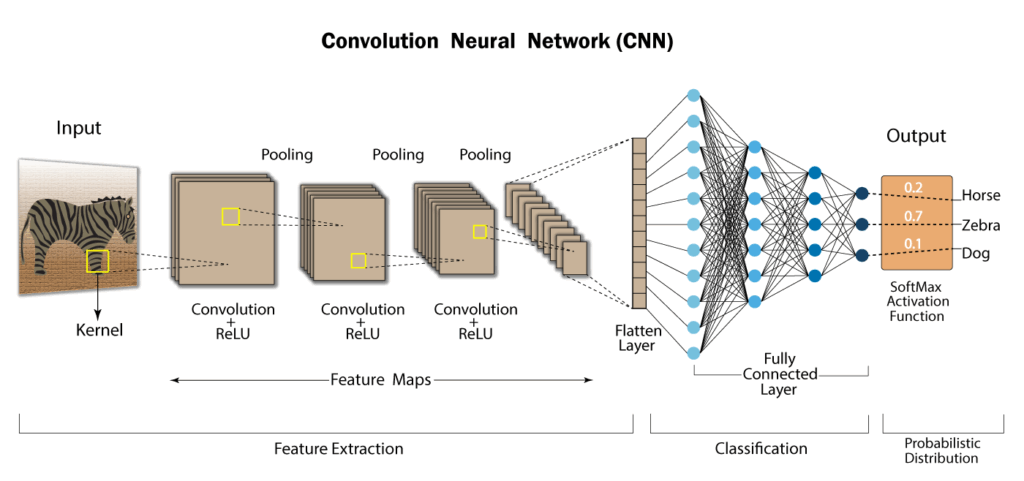
画像認識AIの“エンジン”とも言えるCNN は、カメラ画像や医用スキャン、衛星写真といった2次元データの空間構造を保ったまま特徴量を自動抽出できるディープラーニングアルゴリズムです。
歩行者や標識を瞬時に見分ける自動運転、肺がんを検出する診断AI、マスク越しでもロック解除できるiPhoneのFaceIDなど、最前線のサービス・プロダクトの多くが CNN を基盤にしています。
そんな便利なCNNですが、当然扱う際のメリット・デメリットをはらむため、以下にその概要を記しておきます。
| メリット | デメリット | |
| 性能 | 画像・物体検出で高精度を達成しやすい | 長距離依存を持つTransformer系に劣る場合がある |
| 効率 | 特徴量エンジニアリング不要 | 大量のラベル付き画像と計算資源が必要 |
| 汎用性 | 分類・検出・特徴抽出などタスク横断可 | 3Dなどへの適用困難 |
| 開発 | TensorFlow・PyTorchなどと事前学習モデルが豊富 | 最新アーキテクチャには少し弱い |
Meta(Facebook)による導入事例が豊富
十数年前からMeta社はテックカンパニーの中でもAI研究開発にリソースを大量に注ぎ込んでいますが(Facebook AI Research)、中でも彼らは人間の顔検出や人間のテクスチャを特定するなどのAIモデル開発に注力してきました。
そのモデルアルゴリズムのほとんどがCNNを採用しており、業界内ではCNNの代表事例としてFacebook AI Researchを取り上げることもしばしば。
Vision Transformer(ViT)
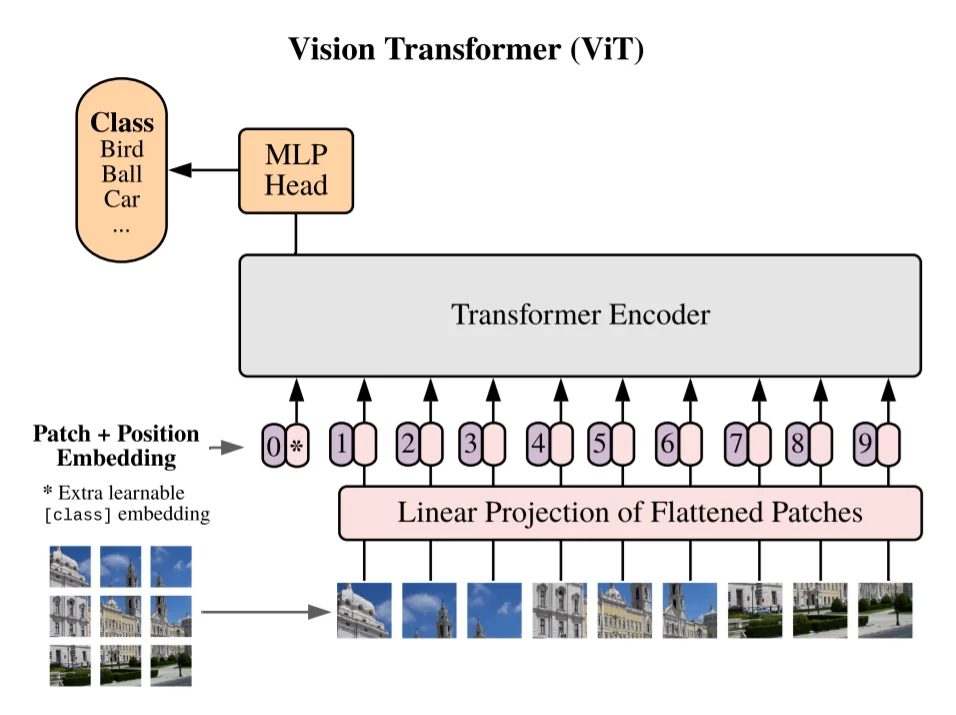
ViTは、Google検索エンジンに取り込まれているBERTなどで成功したTransformerを画像へ転用したモデルで、現代の画像生成AIの中核技術といえます。
具体的な構造としては、
画素を16 × 16ピクセルなどの「パッチ」に分割
↓
1次元ベクトル化
↓
位置埋め込みを付与してSelf-Attentionに流し込み。
これにより画像全体を直接モデリングでき、画像を構成するピクセルが遠く離れた領域同士の相互作用も逃さず学習可能となっており、画像そのものが何を表しているかを意味単位で理解するような振る舞いを見せます。
一言でまとめると、ViTは「人間が目に映る映像を処理する時とほぼ同じ動きを再現したAIアルゴリズム」となります。
OpenCV(ライブラリ)
OpenCVは2000年にIntelが公開し、現在は非営利のOpen Source Vision Foundationが管理する世界最大級のコンピュータビジョンライブラリです。
2500以上のアルゴリズムを備え、C++実装を核にPython、Javaなど多言語バインディング を提供していることから非常に人気で汎用性の高いライブラリとなっています。
Tensorflow(ライブラリ)
TensorflowはGoogle Brainが2015年~2017年に公開したエンドツーエンド機械学習フレームワークで、言語はPython/C++/CUDA を中心に、OSはLinux・macOS・Windows・Androidまで幅広い環境をサポートしています。
2025年の最新版ではKeras3が標準搭載され、Python3.12対応やWindows CPUビルドの移行など大規模アップデートが行われました。
画像認識AIの種類
画像認識AIは、前述の通り用途や目的範囲の多様性により、さまざまな種類が存在します。それぞれのタイプは課題に対応するため最適化されており、独自のアルゴリズムが採用されています。
ゆえに、一概に画像認識AIに関して詳しくない人からすれば、混乱してしまう場合もあるでしょう。
本節では、主な画像認識AIの種類についてそれぞれの特徴や利点を概観していきたいかと思います。
画像分類
画像分類は、画像認識AIにおける基本的なタスクであり、画像を固定のクラス集合にマッピングするものになります。
簡単に言うと、画像がどのカテゴリに属するかを自動的に判別するアルゴリズムです。
用途でいうと、医療診断や製造検品など、判断を“一枚の画像”で完結させたいシーンなどになります。
使用されるアルゴリズムは、CNNまたはTransformer系となることが多いです。
物体検出
物体検出は、画像認識AIにおける高度なタスクで、画像内の複数物体を「カテゴリ+位置」として同時に推定します。画像のどこに何があるかを一度に教えてくれるアルゴリズムと言えます。
用途としては、自動運転の周囲認識、監視カメラのリアルタイム異常検知、倉庫の在庫管理など、瞬時に環境を把握したいシーンで活躍します。
使用されるアルゴリズムは、高精度のFaster R-CNNといったCNN系が中心ですが、近年は前述のViTなどTransformer系アプローチも勢いを増しています。
文字認識(OCR)
文字認識(OCR)は、画像や映像に写った活字・手書き文字を “そのままテキストデータに写し取る” ための技術です。
契約書や、請求書、アンケート用紙など、文字を自動でデータ化したい場面で幅広く使われます。
実装は、CNN、Transformerによる認識が一般的です。
画像認識AIを開発する流れ
画像認識AIの開発には、他のAI開発と同様に段階的なプロセスを踏む必要があります。
そのユニークな点は、他の数値データを扱うAI(需要予測モデルなど)とは違い、データ処理方法が画像に特化したものだったりします。
本説では流れを段階的に解説していきたいかと思います。
※今回はCNN(畳み込みニューラルネットワーク)を想定した開発フローをご紹介します。
画像データを収集
画像認識AIの精度は「どんな画像をどれだけ集めたか」に大きく左右されます。
以下にデータ収集の鉄則3つまとめましたのでご覧ください。
目的に合った画像を特定する
- ゴールの明確化:物体検出なら「多角度・多照明」の画像、文字認識なら「フォント・手書き混在」
- バリエーション確保:背景・サイズ・解像度を意識して“偏らないデータ”を集める
収集手段を選ぶ
| 方法 | 注意点 |
| 公開データセット | タスク特化データが不足しがち |
| ウェブスクレイピング | 著作権・規約の確認必須! |
| 手動ダウンロード | 手間がかかる |
| 自社データの撮影・蓄積 | リソースコストに注意 |
リーガルチェック
- ライセンス:商用利用可否など
- 個人情報:顔・車両番号などの情報は注意
- 著作権:著作権法第30条の「享受」に関する解釈
データ整形・前処理
画像を収集し終えればそれで良しというわけではありません。端的に、収集した画像データはそのままでは学習に不向きです。
“整えてから学習させる”という作業が高精度モデルを作るためには必要になってきます。
以下にデータ整形の定番フローを記します。
データクレンジング
- 欠損値の除去:壊れた画像、極端に暗いものなどを除去
- 重複チェック:同一画像の多重学習は過学習を起こしがち
- 解像度統一:サイズ統一のためのリサイズ
正規化・標準化
- 標準化:初期学習を安定させる
- カラー空間統一:RGB/BGR を混在させない
特徴量抽出・選択
- データオーグメント:画像を回転させてデータの水増し(やり過ぎ注意!)
- ラベル整形:画像データを0, 1の2進数配列で表現する
学習
学習は“前処理で整えた画像+ラベル”を使い、モデルがパターンを吸収する核心的な工程です。
CNN(畳み込みニューラルネットワーク)の学習では、データの特徴量を「抽象的な特徴→具体的な特徴」という順番で捉えさせていくことが基本です。
なお、こちらの具体的なイメージのつきやすい解説は、Part2にて“実際に画像認識AIを開発して”ご説明していきますので、本節では割愛とさせていただきます。
評価
モデルの学習が終わったらその時点でヨシ!というわけではありません。
ここからさらに「本当に使えるか?」を客観指標でチェックするのが評価プロセスです。
検証データの用意
まず、学習データとは別に「評価または検証データ」というものを用意します。データカラムや構造は学習データと同様のものを扱いますが、ここで扱うものは「学習には一切使用しなかったデータ」を用意する必要があるのです。
つまり、そのモデルにとって初体験となるデータを渡してやり、本番環境でもちゃんと認識ができるのかを客観的に評価するということになります。
評価指標
また、検証データをモデルに与えた際に評価する基準も相場が決まっています。
| 指標 | 役割・意味 |
|---|---|
| Accuracy | ・正解率。全体において何%当たったのか ・95%以上であると好ましい |
| Confusion Matrix | ・誤分類パターンの可視化 ・どこで間違ったのかをグラフ分布し、改善 |
この評価時点で、例えばモデルのAccuracyがあまりにも低ければモデルの組み方が間違っています。逆に100%と異常にハイスコアを出し続ける場合、データセットが偏り過ぎている場合もあります。
評価を持って、最終的に「このAIモデルで勝負しよう」となるわけですね。
Part2: 実際に開発して仕組みを解説
さて、ここまで画像認識AIについて概論や理論をご紹介しましたが、筆者は記事の執筆中に「実際に作っている風景が見えないと分かるものも分からないかもな」と思いました。
ということで、本記事をPart1とし、次回の記事Part2にて“実際に画像認識AIモデルを開発”して解説に臨みたいかと思います。
最後までお読みくださりありがとうございました。
この記事の著者

児玉慶一
執行役員/ AI・ITエンジニア
SNS
![]()
愛称: ケーイチ
1999年2月生まれ。大学へ現役進学後数ヶ月で通信キャリアの営業代理店を経験。営業商材をもとに100名規模の学生団体を構築。個人事業主として2018年〜2020年2月まで活動したのち、2020年4月に広告営業事業を営む株式会社TOYを創業。同時期にITの可能性を感じプログラミングを始め、現在はITエンジニアとして活動中。2021年にLeograph株式会社に参画し、AI研究開発やWebアプリ開発などを手掛ける。 「Don't repeat yourself(重複作業をなくそう)」「Garbage in, Garbage out(無意味なデータは、無意味な結果をもたらす)」をモットーにエンジニア業務をこなす。
【得意領域】
業務効率化AIモデル開発
事業課題、戦略工程からシステム開発
Webマーケティング戦略からSaaS開発