個人でもできるAI開発とは?作り方や言語ライブラリについて解説!



人工知能(AI)の技術は、近年急速に進化し、さまざまな分野での応用が広がっています。このような中、個人がAI開発に挑戦する機会も増えてきました。
また、企業でも「個人(フリーランス)へAI開発を委託することはできるのか?」という疑問を持つ声も少なくないようです。
本記事では、個人でも取り組めるAI開発の概要から、具体的な作り方、使用するプログラミング言語やライブラリに至るまで、詳細に解説いたします。
この記事を通じて、AIに関する知識が少ない方でも理解しやすく、実践的なAI開発の方法を学ぶことができるようになります。
個人でもAI開発はできるのか?
![[機械学習]初心者に向けてアヤメ分類を一から解説してみた #Python - Qiita](https://www.leograph.co.jp/wp-content/uploads/2025/06/image.png)
結論から言いますと、個人でもAI開発に取り組むことは十分可能です。
しかし、コンピューティングリソースや予算の制約により、プロジェクトの規模は限定される傾向があります。 例えば、AI界隈で有名なアヤメの種類判別のような比較的小規模なタスクであれば手がけやすいですが、大規模なデータセットを用いたディープラーニングの応用は、個人の環境では現実的ではない場合が多いです。
以下では、個人が取り組めるAI開発の具体例やその難易度について詳しく解説します。
小規模AI開発の難易度
ここでは、個人が取り組むにあたって比較的容易であり、実現可能なプロジェクトのことを「小規模AI開発」と呼称します。
冒頭でもお話ししたような決定木を用いた簡易的なAI判別は、理解しやすく実装もしやすいため、初心者に適しています。また、データセットが小規模なクラスタリングも、限られたリソースで効果的に行うことが可能です。
SNSのエンゲージメント予測といった具体的な応用に関しても、複雑怪奇な予測をしない限りは小規模なデータを活用することで精度の高いモデルを構築することができます。
上記のような例は必要なコンピューティングリソースやデータ量が限定的であるため、個人でも手軽に始められます。
| 項目 | 小規模AIの特徴 | 主なメリット |
|---|---|---|
| アルゴリズム例 | 決定木・ランダムフォレスト・k-means・ロジスティック回帰など、パラメータが少なく解釈しやすいモデル | 実装が容易 |
| データ規模 | 数MB程度の CSV・Excel・JSON ファイル | 収集・前処理コストが低い |
| 計算リソース | PCのCPUで十分 | 自宅PCで学習可能 |
| 開発スピード | 数時間でMVPを構築・検証 | 学習サイクルが早い |
| デプロイ & 運用 | Flask / FastAPIで軽量 Web API化 | 運用コストほぼゼロ |
中規模AI開発の難易度
小規模なプロジェクトと比較して複雑性が著しく増し、個人が取り組む際にはいくつかの重要な課題が伴う可能性のあるものを「中規模AI開発」とします。
教師あり学習と教師なし学習を組み合わせたような高度なモデルの構築や、大規模なデータセットを用いたクラスタリング処理、さらには株価予測といった精度の高い予測モデルの開発などが挙げられます。
つまり、複雑性の高いAIモデルを正確に評価するために膨大なデータの収集と前処理が必要となるため、データ管理能力や効率的な処理技術が求められます。
また、モデルの選定やハイパーパラメータの最適化には専門的な知識と経験が必要であり、試行錯誤のプロセスが多くを占めます。
加えて、計算リソースの確保も重要な要素であり、高性能なハードウェアやクラウドサービスの利用が不可欠となります。 その際、個人のお財布だけで耐えられるレベルでは中規模とはいえないため、ある程度資金力のある個人であれば実現可能=リソース問題が壁となるということになります。
| 項目 | 中規模AIの特徴 | 主な課題 |
|---|---|---|
| アルゴリズム例 | 深層学習(CNN/RNN/Transformer)、勾配ブースティング、大規模クラスタリング、教師あり+教師なしハイブリッド | モデル選定とハイパーパラメータ最適化が困難/計算コスト高 |
| データ規模 | 数GB〜数百 GB | 前処理・ETL パイプライン必須/ストレージコスト増 |
| 計算リソース | 単一〜複数GPU | 個人負担が大きいコスト管理 |
| 開発スピード | 数週間〜数ヶ月でプロトタイプ | 実験追跡がないと再現性低下 |
| コスト管理 | GPU 課金・データ転送料・ストレージ増加 | コスト予測スキル必須 |
大規模AI開発の難易度
大規模なAI開発は、企業規模での取り組みが主流であり、個人が同等のプロジェクトを実施することは非常に困難です。
これにはいろいろな理由がありますが、一次情報を必要とするデータ収集が個人では難しかったり、費用や、高次元データを扱うAIモデルの構築に伴う技術的な複雑さが大きな要因となります。
さらには、生成AIを筆頭にしたCPU・GPUといった計算資源の大量消費も大規模AI開発の特徴であり、これらを継続的に利用するためには相応の投資が必要です。
データの収集および管理においても、多岐にわたるデータソースから信頼性の高い情報を集約するインフラの整備が不可欠です。これを企業では独自に収集することができるために、個人では十分な基盤を構築することが難しい場合が多いです。
これは、何も個人に限った話ではありません。企業で開発を行うにも、データを集める体制が整っていなかったり、予算規模について予想ハードルを下げすぎても同じです。
| 項目 | 大規模AIの特徴 | 主な課題 |
|---|---|---|
| アルゴリズム例 | 数十億〜数兆パラメータの基盤モデル(GPT-系、拡散モデルなど)・マルチモーダル統合 | 精度-速度-コストのトレードオフ |
| データ規模 | 数 TB〜PB級、テキスト・画像・音声・時系列など多様な一次データ | ガバナンスと品質管理が必須 |
| 計算リソース | 数百〜数千 GPU/TPU:DGX B200 (Blackwell)、H100/H200、Cloud TPU v5p など | リソース確保・クラウド課金が高額 |
| 開発スピード | 数か月〜半年で PoC→本番、ステージング環境も1年単位 | 実験追跡・がないと再現性崩壊 |
| モデル最適化 | 分散 HPO・混合精度・スパース化・量子化・LoRA 微調整 | メモリ制約/訓練不安定/試行回数爆発 |
| デプロイ & 運用 | Triton/KServe で推論マイクロサービス化、A/B テストと継続学習 | レイテンシ最適化・GPU オートスケール・監視が必須 |
AI開発の具体的な予算感について詳しく知りたい方は以下の記事をご覧ください。
AIを作るための基礎知識
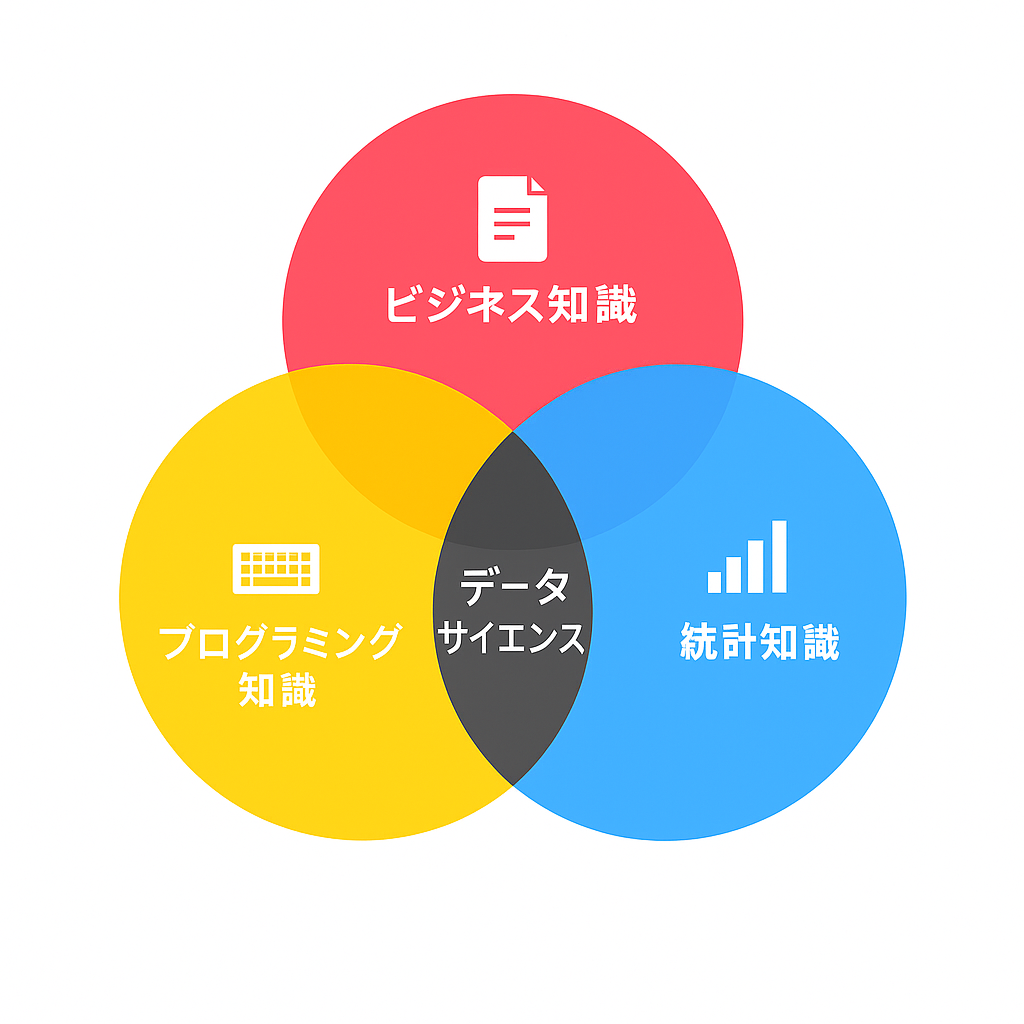
個人でも開発ができるとは言いつつも、AIの開発には、複数の専門分野にわたる基礎知識が必要です。
データの分析や解釈を行うための統計学、適切なモデル選択や評価、機械学習の原理や手法を理解することが求められます。個人・企業に関わらず、AIを開発しようとする場合はこれらの基礎知識を体系的に習得することが重要です。
本節では各種基礎知識について詳しく解説していきます
統計の知識
AIの開発において、統計学の知識は不可欠な基盤となります。
AIは、言ってしまえば確率論の応用であり、データの不確実性や変動性を扱うために統計的手法が重要な役割を果たします。
確率分布、期待値、分散などの基本的な確率論の概念を理解することで、データの背後に潜むパターンや傾向を正確に捉えることが可能となります。
また、統計的推定や仮説検定の手法を用いることで、モデルの信頼性や有効性を評価し、適切な改善策を講じることができます。
例えば、回帰分析などの技術は予測モデルの精度向上に直接的な影響を及ぼします。つまり、統計学の知識がないことはAIを作る土俵にすら立たないと言い換えることもできます。
機械学習の知識
機械学習の知識は、効果的なAIモデルの設計・構築・最適化に不可欠です。
以下に、筆者が包括的に理解しておくといいと思う機械学習の概念を表にまとめてみました。
| カテゴリ | 内容 | 具体例・技術名 | 目的 / 特徴 |
|---|---|---|---|
| 学習カテゴリ | 教師あり学習 | 線形回帰, ロジスティック回帰, 決定木, ランダムフォレスト | 正解ラベルあり、予測・分類 |
| 教師なし学習 | k-means, PCA | 構造・パターン発見、ラベルなし | |
| 強化学習 | Q学習, DQN, PPO | 報酬最大化による | |
| 代表アルゴリズム | シンプルなモデル | 線形回帰, ロジスティック回帰 | 高速 |
| 複雑なモデル | ランダムフォレスト, SVM, XGBoost | 非線形構造の学習 | |
| 深層学習 | CNN, RNN, Transformer | 特徴抽出+高性能予測 画像認識などに使われる | |
| 訓練と評価 | 損失関数・最適化 | MSE, クロスエントロピー, SGD, Adam | モデルの学習を誘導 |
| 過学習対策 | L1/L2正則化, Dropout, 交差検証 | 汎化性能の維持 | |
| 評価指標 | 精度, 再現率, F1値, ROC-AUC | タスクに応じた多面的評価 |
このように、機械学習の知識はAI開発における多岐にわたる工程で不可欠な要素となっており、理論的な理解と実践的なスキルの双方をバランスよく習得することが大事です。
この点においてもお分かりの通り、AI開発はデベロッパー(開発者)にとっての勉強ハードルが高いため、ゼロからAIを開発できる事業者が多くない理由が垣間見えるかと思います。
また、AI開発に必要な具体的な技術アセットについては以前ご紹介した記事が参考になるかと思います。
プログラミングの知識
プログラミングの知識は言わずもがなAI開発の基本的な要素です。
AIモデルの設計や実装には、効率的かつ効果的なコードを書くためのプログラミングが求められます。
後述するPythonはその豊富なライブラリとコミュニティのサポートにより、AI開発の主要言語として広く採用されています。
また、オブジェクト指向プログラミング(OOP)の概念を理解し、再利用可能でメンテナンスしやすいコードを書く能力も重要です。
並行して、デバッグやテストの技術も欠かせません。AIモデルの性能を最大限に引き出すためには、コードの正確性と効率性を確保することが求められます。
総じて、幅広いプログラミング知識と実践的なスキルの習得が、AI開発の成功を支えると言えます。
AIの作り方
本節では、AIを開発するために必要な具体的手順を紹介します。
AI開発は複数の段階に分かれており、各ステップごとに適切なアプローチが求められます。要件定義、質の高いデータの収集など、各プロセスにおいて抜け目のないアクションが必要となるため、注意が必要です。
ステップ1: 目的の明確化
まず第一歩として、プロジェクトの目的を明確に定義することです。目的の明確化は、開発プロセス全体の方向性を決定し、適切なリソース配分や技術選定において重要な役割を果たします。
これは特段AI開発に限った話ではなく、すべてのシステム開発における重要なポイントです。
具体的には、以下の点を検討することが重要です。
- 課題・ニーズの特定
- データ分析による業務効率化や顧客サービスの自動化など、AIで解決すべき具体的な問題を明確にする
- AI活用の具体化
- 特定した課題に対してAIがどのように貢献できるかを具体的にイメージし、必要なAIモデルの種類やデータの特性を見極める
- 成功基準
- 精度の目標値、納期、予算などの明確な成功基準を設定し、プロジェクトの進捗評価と必要な調整を行う基準を確立する
- 関係者間での共有
- プロジェクトの目的を関係者全員で共有し、共通理解を持つことで、チーム一丸となった目標達成を可能にする
これらの要素により、AIプロジェクトの基盤となる明確な目的設定が実現されます。
目的の明確化を徹底することで、AI開発プロジェクトの成功率を大幅に高めることが期待できます。
ステップ2: データ収集と前処理
第二段階は「データ収集と前処理」です。
AIはただ単にデータをたくさん集めればいいというものではなく、必要に応じて適切な処理を行う必要があります。この辺りを理解せずに闇雲にAIモデルへデータを渡そうとすると、後述の評価段階で正しい評価が行えなくなります。
データ収集の手順
| ステップ | 詳細 | 例 |
|---|---|---|
| 1. データの特定 | モデルの目的に適したデータを選定 | ・画像認識AI:様々なカテゴリの画像データ ・自然言語処理:大量のテキストデータ |
| 2. 収集手段の選定 | 適切な取得方法を選択 | ・公開データセット ・スクレイピング ・自社データの活用 |
| 3. 法的確認 | ライセンスやプライバシーに関する制約を確認 |
データ前処理の手順
| 処理内容 | 説明 | 効果 |
|---|---|---|
| 1. データクレンジング | ・欠損値や異常値の処理 ・不必要なデータの削除 | クリーンなデータセット構築 |
| 2. 正規化・標準化 | データスケールを統一 | ・学習効率の向上 ・アルゴリズムによる悪影響を軽減 |
| 3. 特徴量の抽出・選択 | ・有用な特徴を抽出 ・不要な特徴を削減 | ・モデルの複雑さを抑制 ・過学習リスクの低減 |
| 4. データの分割 | 訓練・検証・テストデータへの分割 | モデルの汎化性能評価が可能 |
最終確認
| 項目 | 内容 | 目的 |
|---|---|---|
| データの可視化と確認 | 前処理結果の視覚的確認 | 潜在的な問題点の早期発見と修正 |
データ収集と前処理は時間と労力を要する工程ですが、この段階を丁寧に行うことで、後続のモデル学習や評価がスムーズに進行し、高性能なAIを構築するための確固たる基盤を築くことができます。
ステップ3: モデルの選択と学習
第三段階は、適切なモデルの選択と実際に学習を行う段階になります。
ここでは、収集し前処理を行ったデータを基に、具体的な機械学習モデルを選定し、効果的に学習させるための手順と注意点を解説します。
①モデル選択
まず、解決したい問題に対応してどのモデルを選択するかを決定します。
| 問題の種類 | 適用可能なモデル |
|---|---|
| 分類系 | ・ランダムフォレスト ・ニューラルネットワーク |
| 回帰系 | ・線形回帰 ・決定木回帰 |
| 大量・複雑なデータ処理 | ディープラーニングモデル |
②ハイパーパラメータ最適化
ハイパーパラメータの最適化は、機械学習モデルの性能を最大限に引き出すためのプロセスです。モデルのパラメータが学習過程で自動的に調整されるのに対し、ハイパーパラメータは人間が事前に設定する必要があり、その選択がモデルの学習効率と最終的な性能を大きく左右します。
③過学習防止のためのアクション
AIモデルは、学習に使うデータ傾向が偏ってしまったり、余計なデータノイズがあったりすると「過学習」という「AIによる思い込み」が激しくなってしまうことがあります。
このステップではそれを防ぐためにいくつか取るべきアクションがあります。
| 手法 | 効果 |
|---|---|
| データ分割 | モデルの汎化性能を評価 |
| 正則化 | モデルの複雑さを抑制 |
| クロスバリデーション | モデルの安定性と信頼性を向上 |
④最終評価
| 評価項目 | 内容 | 重要性 |
|---|---|---|
| 訓練データへの適合度 | モデルがどれだけ訓練データを正確に学習したか | 基本的な性能指標 |
| 汎化能力 | 未見データに対する予測精度 | 実運用での信頼性を左右 |
| 性能評価方法 | 検証データ・テストデータを活用した厳密な評価 | 実際の運用環境での信頼性確保 |
このように、AIを実際に学習させる際の段階においても、複数の工程があることがわかります。
適切なモデルを選び、効果的に学習させることで、高性能で信頼性の高いAIシステムを実現することが可能となります。
おすすめ言語とライブラリ
AI開発を効果的に進めるためには、適切なプログラミング言語とライブラリの選定が重要です。
本節では、初心者から上級者まで幅広く支持されている言語とライブラリについて詳しく解説します。まずは言語について紹介し、強力な機械学習ライブラリであるscikit-learnについて掘り下げていきます。
Python
Pythonは、人工知能(AI)開発において最も広く利用されているプログラミング言語の一つです。その高い人気の理由は、シンプルで読みやすい文法、豊富なライブラリにあります。
これにより、初心者から専門家まで幅広い層が効率的にAIモデルの開発を行うことが可能となっています。
PythonのAI開発における主要ライブラリ
| 分野 | 主要ライブラリ |
|---|---|
| 機械学習・深層学習 | TensorFlow, PyTorch, Keras, scikit-learn |
| データ処理 | Pandas, NumPy |
| データ可視化 | Matplotlib |
総じて、PythonはAI開発における信頼性が高く、効率的な選択肢として推奨される言語です。
scikit-learn
特に、機械学習では、scikit-learnという強力なライブラリが提供されており、個人のAI開発において非常に有用です。このライブラリは、シンプルで一貫性のあるAPI設計を持ちながらも使いやすく設計されており、初心者から専門家まで幅広いユーザーが迅速にプロトタイプを作成し、実際の問題に適用することを可能にします。
さらに、scikit-learnは分類、回帰、クラスタリング、次元削減、モデル選択など、多岐にわたる機械学習アルゴリズムを提供しており、さまざまなデータサイエンスの課題に対応可能です。特に、データ前処理や特徴量エンジニアリングのためのツールが充実しているため、欠損値の補完やデータの正規化、カテゴリ変数のエンコーディングなど、実際のデータセットの複雑な前処理作業も効率的に実施でき、大量のデータを効率的に扱い、洞察を得ることができます。
また、交差検証やグリッドサーチといったモデル評価・選択機能により、最適なパラメータの探索が容易になり、信頼性の高いAIシステムの構築が実現します。PandasやNumPyなどの他のPythonライブラリとの連携もスムーズで、充実したドキュメントやチュートリアルにより、独学での習得も容易です。
まとめ
個人によるAI開発は、適切な知識とツールを活用することで十分に実現可能です。本記事では、AI開発の難易度を小規模から大規模まで段階的に分析し、必要となる基礎知識として統計、機械学習、プログラミングの重要性を強調しました。
しかし、ハードルが高い分野があることも十分に理解いただけると幸いです。
筆者としては、AI開発は適切なナレッジを兼ね備えた会社に依頼することが何よりも安全かと思います。
この記事の著者

児玉慶一
執行役員/ AI・ITエンジニア
SNS
![]()
愛称: ケーイチ
1999年2月生まれ。大学へ現役進学後数ヶ月で通信キャリアの営業代理店を経験。営業商材をもとに100名規模の学生団体を構築。個人事業主として2018年〜2020年2月まで活動したのち、2020年4月に広告営業事業を営む株式会社TOYを創業。同時期にITの可能性を感じプログラミングを始め、現在はITエンジニアとして活動中。2021年にLeograph株式会社に参画し、AI研究開発やWebアプリ開発などを手掛ける。 「Don't repeat yourself(重複作業をなくそう)」「Garbage in, Garbage out(無意味なデータは、無意味な結果をもたらす)」をモットーにエンジニア業務をこなす。
【得意領域】
業務効率化AIモデル開発
事業課題、戦略工程からシステム開発
Webマーケティング戦略からSaaS開発