
【Part2】画像認識AIの仕組みとは?実際に開発して解説してみた【図解】



※こちらの記事は前回の記事『【Part1】画像認識AIの仕組みとは?実際に開発して解説してみた』の続編となります。まだ前回をご覧になっていない方はそちらをご覧になってください。
前回に引き続き、今回は実際に画像認識AIを筆者が独自に開発をして、その様子を記事をご覧の皆さまへ共有します。
その上で、AIモデルを開発する時の流れや困難なポイントについてをご紹介しますので、ぜひ参考にしていただけますと幸いです。
前回のあらすじ
Part1では画像認識AIの仕組み、概論についてご説明しました。
そこではCNN(畳み込みニューラルネットワーク)などの比較的ボリュームとタスクの複雑性が低いモデルについて集中的に解説してまいりました。逆に、高次元の推論を要する場合はTransformerなどを扱うといいとも解説しました。
しかし、概論の時点ですでに専門用語などが出てきて、イマイチ理解に及ばない場面もあったかと思います。
そこで今回はCNNモデルを実際に開発する流れをお見せし、世間一般でも扱われる画像認識AIの仕組みを体系的に学べるような記事にしていきたいかと思います。
今回開発するAIモデルについて
では、早速AIモデルの開発に取り掛かりたいところですが、前回もお伝えした通り「AIは事前の準備が大切」ですよね。
事前準備とは「何を実現したいか」「モデルの種類は何か」「見合ったデータを用意できるか」などです。
画像認識AIでハンバーガーとサンドイッチを分類してみよう

今回はハンバーガーの画像とサンドイッチの画像を学習させたモデルを作り、最終的にAIに「これはどっちですか?」と聞いた際に正確に判別ができていれば良しとしましょう。
なぜこの二種類の料理を選んだかというと、上記の画像をご覧になればお分かりかと思いますが、似ていませんか?
というのも、ボクたち人間は一目見れば一発で「これはハンバーガー、こっちはサンドイッチ」と分かりますが、よく考えてみると両者の構造と見た目は非常に似ています。何かをパンで挟み、焼き色をつけたり、お肉を使ったりと。
重要なのは、僕たちの脳が一瞬で料理の違い判断するに至る過程をAIに学ばせられるかという点です。
なので、今回はハンバーガーとサンドイッチに特化した画像認識AIモデルを作ることにします。

人間にとっては普通の光景も、AIにとっては初体験なものです
CNNモデル
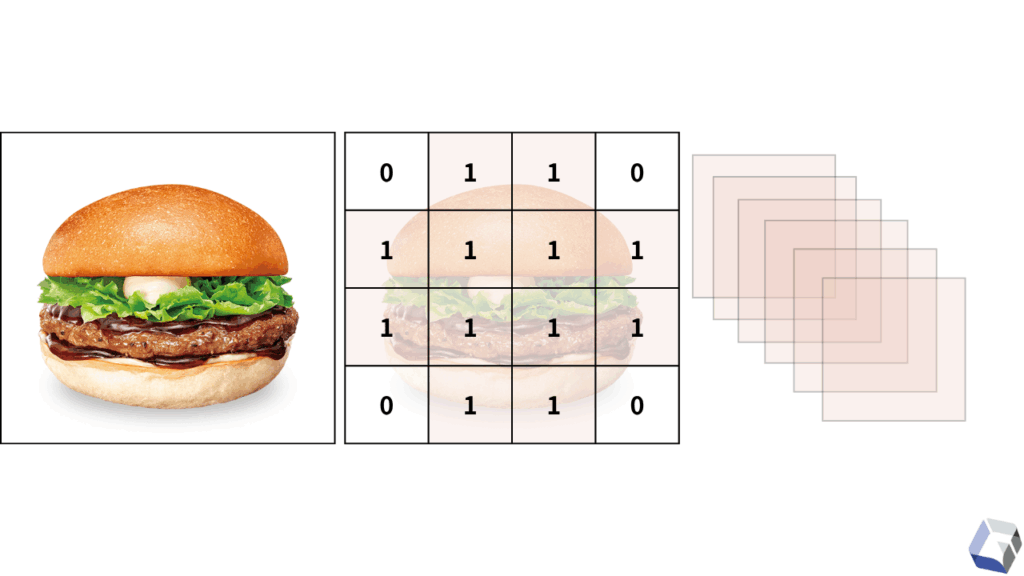
今回の学習手法は、前回の記事でもお伝えした『CNN(畳み込みニューラルネットワーク)』を扱うこととします。
「畳み込み」とは何なのか
これまで概論として解説してきたCNNですが、もう少し詳しく解説していきます。
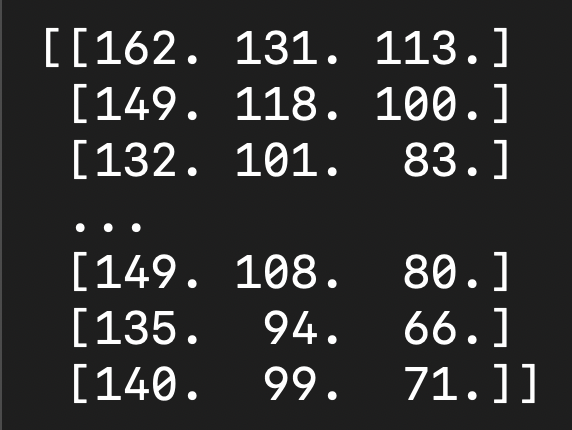
まず、画像データというものは「縦ピクセル数 * 横ピクセル数 * 色を表す数値(RGB)」で成り立っています。これを計算式で組み合わせることで、画像データは数値配列(3次元配列)として表すことができます。
画像が数値配列に変換された時点で、プログラムでも画像の構成を読み取りが可能な状態となります。

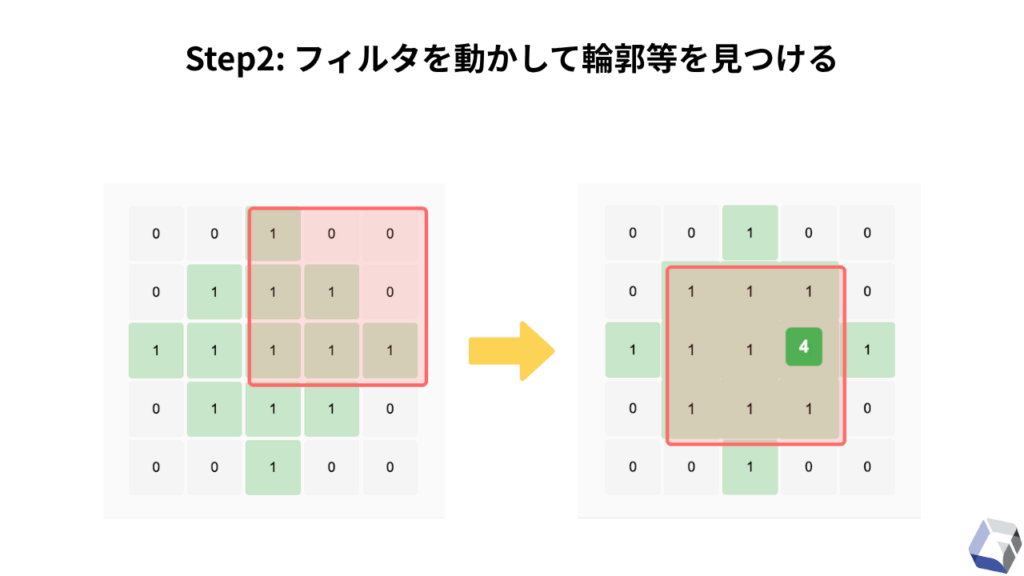
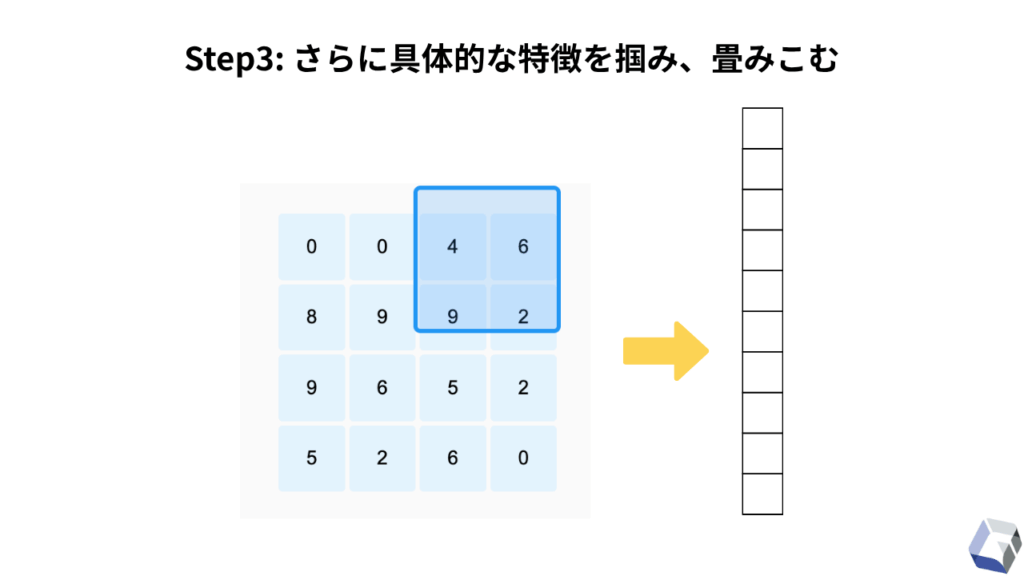
CNNは、この数値配列に変換された画像データを「抽象的な特徴→具体的な特徴」という順番で深く抽出していき、最終的な正解ラベル(ハンバーガー = 0, サンドイッチ = 1)と結合(1次元配列化)させるまでの工程のことを指しています。
これを実現するための工程が何層にもわたるニューラルネットワークを採用する必要があるために、この手法は『CNN = Convolutional Neural Network(畳み込みニューラルネットワーク)』と呼称されています。
学習データの準備方法

では、いよいよAIモデルの開発へと移りたいかと思います。
今回はハンバーガーとサンドイッチの画像データが大量に必要となるため、Web上でそれぞれに該当するキーワードでヒットしたものを片っ端からダウンロードしました。
しかし、AIモデルを学習させるためには学習データを適切に準備しなければなりません。
データクレンジング
まず、データをそのまま扱うことは絶対にできないため、データクレンジングを行います。
本節ではAIモデル学習のために行なったことをコードとともにご紹介します。また、データクレンジングについては前回の記事で解説しておりますので、概要はそちらをご覧ください。
画像サイズ統一・低画質データ削除

データ入力において、画像のサイズがバラバラだとモデル学習を行うことができません。これは数値配列同士を計算するときに、配列の形が違うとエラーを引き起こしてしまうためです。
また、画質の粗い画像データも取り除く必要があります。
つまり、CNNを構築する際に必要なデータクレンジングの工程では、画像のサイズを統一し、画質をなるべく一定範囲に留めることが必要になります。
# python
from pathlib import Path
from typing import List
from PIL import Image, UnidentifiedImageError, ImageOps
def resize(img_path: Path, save_dir: Path, px: int = 100) -> Path:
"""
画像を100pxでリサイズして保存。
- img_path : 入力画像パス
- save_dir : 保存ディレクトリ
- px : 出力画像の一辺ピクセル数
- ピクセルが100以下の場合は削除(粗い画質のものはいらない)
"""
try:
with Image.open(img_path) as im:
if min(im.size) <= px:
img_path.unlink(missing_ok=True)
print(f"Removed: {img_path}")
return None
save_dir.mkdir(parents=True, exist_ok=True)
# 出力パス
out_path = save_dir / f"{img_path.stem}{img_path.suffix}"
if not out_path.exists():
# 正方形リサイズ
ImageOps.fit(im, (px, px), Image.LANCZOS).save(out_path)
return out_path
except (UnidentifiedImageError, OSError):
img_path.unlink(missing_ok=True)
print(f"Removed (corrupt): {img_path}")
return None人間も、ぼんやりとした視界ではモノをハッキリと認識できないですよね
数値配列化・正解ラベル作成
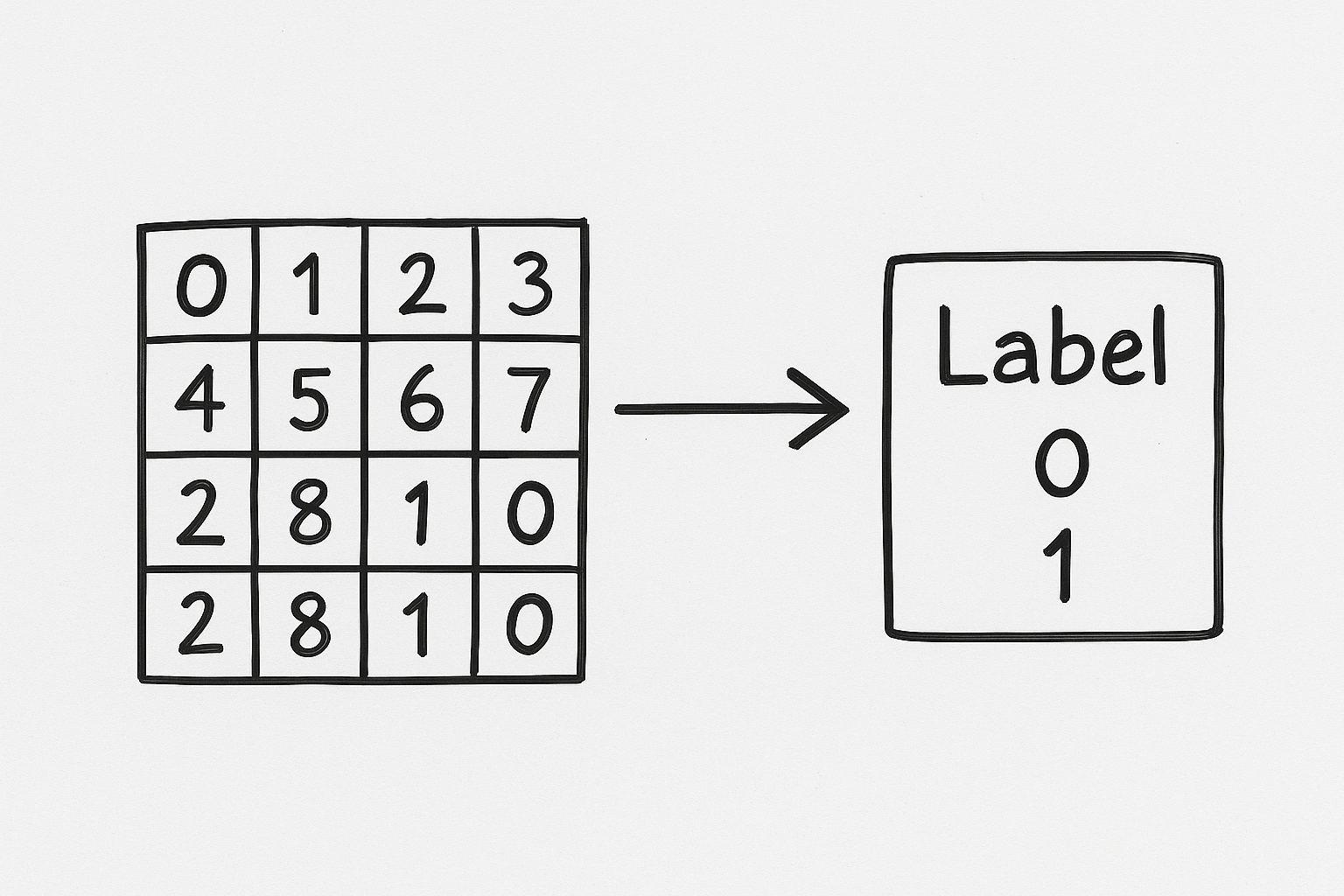
画像のサイズ統一が済んだら、今度は画像データをプログラムが読み込める形(数値配列)へと整形していきます。
また、このときに「どの配列をどっちの分類にすべきか」という正解ラベルも一緒に用意します。
これで、AIモデルにとって「この配列パターンはハンバーガー、こっちはサンドイッチのパターン」と、データの傾向を読み込ませる準備が整います。
import numpy as np
# cleansed_rootはクレンジングの完了した画像を格納したディレクトリのことです
root = Path(cleansed_root)
# 扱うクラス(ハンバーガーとサンドイッチ)を仕分ける
classes = sorted([d.name for d in root.iterdir() if d.is_dir()])
# クラスを数値に変換(ハンバーガー = 0, サンドイッチ = 1)
class_to_idx = {cls: i for i, cls in enumerate(classes)}
X, y_idx = [], []
# クラスごとに画像を全取得し、
for cls in classes:
for p in _iter_images(root / cls):
try:
img = Image.open(p).convert("RGB")
# 画像を配列(3次元配列)に変換してリストへ追加
X.append(np.asarray(img, dtype=np.float32))
# 現在のクラスに対応するラベル(0=ハンバーガー, 1=サンドイッチ)を追加
y_idx.append(class_to_idx[cls])
except UnidentifiedImageError:
# 壊れた画像があればスキップ
continue
# RGB範囲に正規化
X = np.stack(X) / 255.0
y_idx = np.array(y_idx)学習・検証データ分割
データセットの準備が整ったら、事前準備としては最終段階の「データ分割」を行います。
これは、前回の記事でもご説明の通り、データが思った通りに学習されているかを客観的に評価するための方法です。
from sklearn.model_selection import train_test_split
X_train_val, X_test, y_train_val, y_test = train_test_split(
X, y_idx, test_size=test_size, stratify=y_idx, random_state=random_state
)学校の勉強ができても、社会に出た後の事象に対応できなきゃ意味がない的なことです
モデル学習
データセットの事前準備が整い、いよいよモデルの学習を始める工程へと移ります。
CNNを扱い、適切な学習が可能となるようなモデル構成を作るところから始めてみましょう。
モデル構成
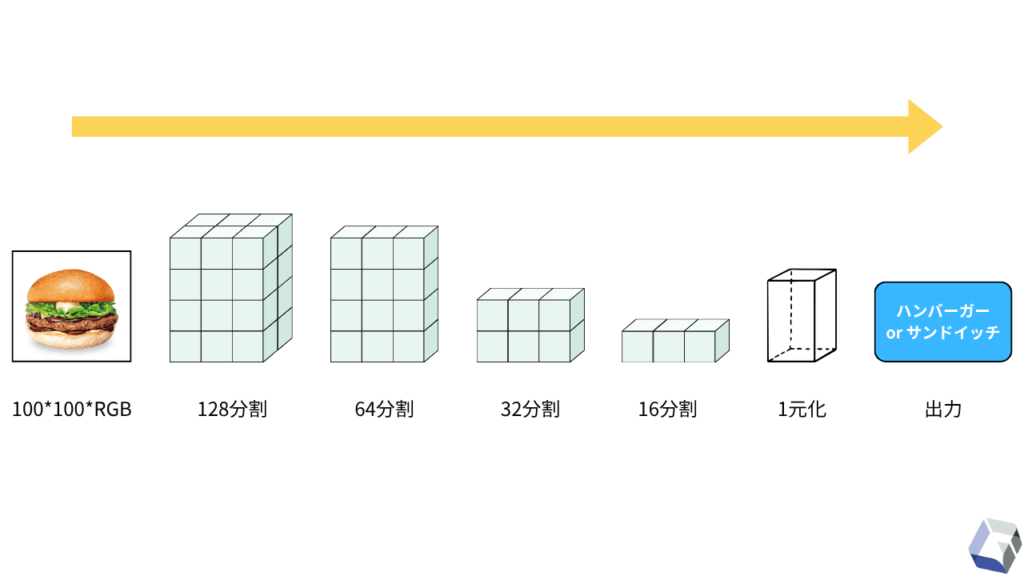
CNNのモデルは、画像データの入力から出力(2択の判断)に至るまで、徐々に「抽象的な特徴→具体的な特徴」という順番で特徴を抽出していきます。
それを忠実に行うために、今回は上記画像のようなニューロン層を追加していきます。
この時点で大事になってくるのが、「何回畳み込ませるのか」「フィルタのサイズをいくつにするのか」という点です。つまり、いかに人間がモデルの骨組みを決めるかによって、学習の精度が変わってきます。
また、モデルの詳しい構成について知りたい方は以下をご覧ください。
Classes : {'hamburgers': 0, 'sandwiches': 1}
Train : (5831, 100, 100, 3) (5831,)
Val : (834, 100, 100, 3) (834,)
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ conv2d (Conv2D) │ (None, 100, 100, 64) │ 832 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ batch_normalization │ (None, 100, 100, 64) │ 256 │
│ (BatchNormalization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ activation (Activation) │ (None, 100, 100, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling2d (MaxPooling2D) │ (None, 50, 50, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ conv2d_1 (Conv2D) │ (None, 50, 50, 128) │ 32,896 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ batch_normalization_1 │ (None, 50, 50, 128) │ 512 │
│ (BatchNormalization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ activation_1 (Activation) │ (None, 50, 50, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling2d_1 (MaxPooling2D) │ (None, 25, 25, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ conv2d_2 (Conv2D) │ (None, 25, 25, 64) │ 32,832 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ batch_normalization_2 │ (None, 25, 25, 64) │ 256 │
│ (BatchNormalization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ activation_2 (Activation) │ (None, 25, 25, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling2d_2 (MaxPooling2D) │ (None, 12, 12, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ conv2d_3 (Conv2D) │ (None, 12, 12, 32) │ 8,224 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ batch_normalization_3 │ (None, 12, 12, 32) │ 128 │
│ (BatchNormalization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ activation_3 (Activation) │ (None, 12, 12, 32) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling2d_3 (MaxPooling2D) │ (None, 6, 6, 32) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ conv2d_4 (Conv2D) │ (None, 6, 6, 16) │ 2,064 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ batch_normalization_4 │ (None, 6, 6, 16) │ 64 │
│ (BatchNormalization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ activation_4 (Activation) │ (None, 6, 6, 16) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ global_average_pooling2d │ (None, 16) │ 0 │
│ (GlobalAveragePooling2D) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout (Dropout) │ (None, 16) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense (Dense) │ (None, 1) │ 17 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 78,081 (305.00 KB)
Trainable params: 77,473 (302.63 KB)
Non-trainable params: 608 (2.38 KB)学習開始
モデルの構成が決まったら、それぞれのデータを読み込ませ、プログラムで学習を開始させます。
学習を開始させると、下記のように学習の進捗を画面上から確認することができます。
# Linux画面
Epoch 1/30
209/209 - 26s - 125ms/step - accuracy: 0.7529 - loss: 0.5150 - val_accuracy: 0.6906 - val_loss: 0.5925 - learning_rate: 1.0000e-03
Epoch 2/30
209/209 - 26s - 124ms/step - accuracy: 0.8096 - loss: 0.4223 - val_accuracy: 0.7218 - val_loss: 0.5160 - learning_rate: 1.0000e-03
Epoch 3/30
209/209 - 25s - 121ms/step - accuracy: 0.8384 - loss: 0.3754 - val_accuracy: 0.8094 - val_loss: 0.4392 - learning_rate: 1.0000e-03
...
# 長いのでエポック4〜27を省略
...
Epoch 28/30
209/209 - 28s - 135ms/step - accuracy: 0.9799 - loss: 0.0848 - val_accuracy: 0.9065 - val_loss: 0.2519 - learning_rate: 1.0000e-05
Epoch 29/30
209/209 - 28s - 132ms/step - accuracy: 0.9813 - loss: 0.0804 - val_accuracy: 0.9053 - val_loss: 0.2502 - learning_rate: 1.0000e-05
Epoch 30/30
209/209 - 27s - 131ms/step - accuracy: 0.9787 - loss: 0.0860 - val_accuracy: 0.9029 - val_loss: 0.2494 - learning_rate: 1.0000e-05ここで注視すべきは「accuracy(正解率)」と「loss(損失)」です。
「accuracy(正解率)」に関しては、読んで字の如く「モデルの予測が正解した回数をモデルが予測した回数で割った数」になります。
「loss(損失)」とは「モデルがどれだけ間違えたかのスコア」で、「予測した確率と正解ラベルの距離(ズレ)」を表します。
今回の正解ラベルはハンバーガー = 0, サンドイッチ = 1と数値に表し、それに対してモデルが“何%の確率で答えに確信を持ったのか”を引くことで表現することができる値です。(実際には対数log式を使います)
モデル評価
学習が終わったら、モデルの学習進捗をもとに評価をします。
ここで効率的にモデルの学習具合を把握するため、先ほどの「accuracy(正解率)」と「loss(損失)」をグラフにプロットしてみます。
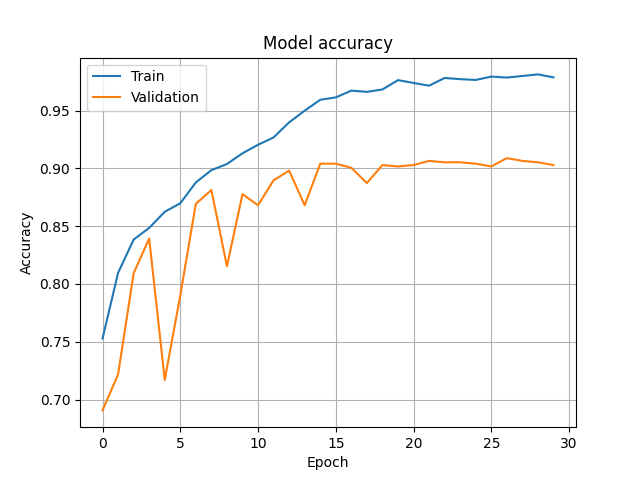
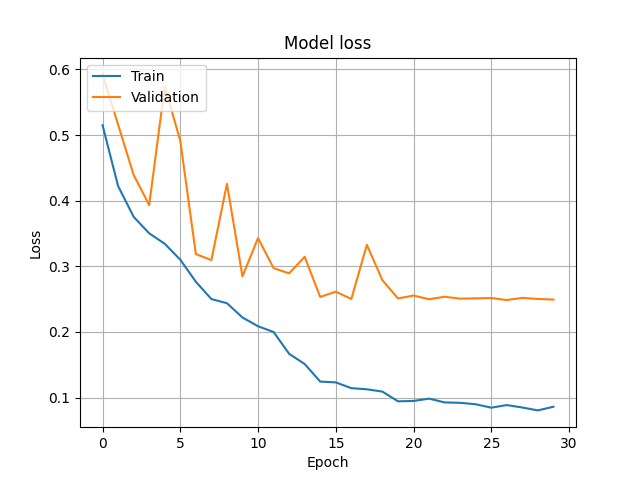
一枚目の画像はモデルのaccuracy、二枚目の画像はモデルのlossをエポック数(モデルの世代交代数)ごとにプロットしたものとなります。
AIモデル開発では、エポック数が増すごとに両者が比例して増える、減るという振る舞いを期待します。もしこの時点でaccuracyが全然上がらない、lossが全然減らないなどの状況が見える場合、モデル構成の見直しやデータクレンジングの甘さなどを疑うといいでしょう。
また、プロット図にある青い線(Train)とオレンジ色の線(Validation)が見えるかと思います。これは前述の「学習・検証データ分割」でご説明のデータの違いで、両者に乖離が少なければ少ないほどモデルの性能はいいと判断します。
もしこの二つがあまりにも離れて見える場合、そのモデルは「過学習」を引き起こしていると言えます。つまり、そのモデルは都合の良いデータに偏って学習している可能性が高いのです。
モデルテスト
学習の進捗を見る限り、概ね今回の目的に沿ったモデルとしては最低限の性能を与えることができたかと思います。
ここで、一度「Web上で拾ってきたランダムな画像を読み込ませてテスト」を行なってみます。
結論、ハンバーガーとサンドイッチのどちらの画像でもしっかりと予測することができ、画像の分類ができているように思えました。
下記にそれぞれの結果を添付しておりますのでご覧ください。
ハンバーガーの画像テスト結果


teriyaki-hamburger.png
python3 predict.py avocado-hamburger.jpg
"avocado-hamburger.jpg" は 98.3% の確率で “ハンバーガー” です
python3 predict.py teriyaki-hamburger.png
"teriyaki-hamburger.jpg" は 100.0% の確率で “ハンバーガー” ですサンドイッチの画像テスト結果


python3 predict.py egg-sandwich.jpg
"egg-sandwich.jpg" は 89.0% の確率で “サンドイッチ” です
python3 predict.py salad-sandwich.jpg
"salad-sandwich.jpg" は 99.9% の確率で “サンドイッチ” ですまとめ
今回、筆者が開発した画像認識AIは、総評としては「しっかりと判定が行えるAI」に育ったと思います。
大事なことは「実現したいこと」「収集するデータの質」「事前準備」「結果を見てフィードバックをすること」の4点にまとめることができます。
本記事を通じて読者の皆さまにAI開発の工程や気難しさの理由を少しでもお伝えすることができたら幸いです。
また、Leographでは画像認識AIの開発をお受けするサービスも承っておりますので、ご興味のおありの方はそちらもご覧いただければと思います。
この記事の著者
児玉慶一
執行役員/ AI・ITエンジニア
SNS
![]()
愛称: ケーイチ
1999年2月生まれ。大学へ現役進学後数ヶ月で通信キャリアの営業代理店を経験。営業商材をもとに100名規模の学生団体を構築。個人事業主として2018年〜2020年2月まで活動したのち、2020年4月に広告営業事業を営む株式会社TOYを創業。同時期にITの可能性を感じプログラミングを始め、現在はITエンジニアとして活動中。2021年にLeograph株式会社に参画し、AI研究開発やWebアプリ開発などを手掛ける。 「Don't repeat yourself(重複作業をなくそう)」「Garbage in, Garbage out(無意味なデータは、無意味な結果をもたらす)」をモットーにエンジニア業務をこなす。
【得意領域】
業務効率化AIモデル開発
事業課題、戦略工程からシステム開発
Webマーケティング戦略からSaaS開発